



Its funny how the little things always hang us up. I get asked frequently what is the difference between git fetch and git pull at least once a week and sometimes it's by the same people. This originally made me think that I was not doing a good job of explaining it but I am now realizing that it's because I didn't have a simple understanding of it.
Stick with me here. I love specifications, "rules that guide" if you will. Once when doing a REST API I decided to attempt to commit to memory Chapter 5 of Roy Fielding's dissertation - it's riveting you should have a read when you have a lot of free time (I personally liked it others might not). I was able to quote it and stand on the dissertation and RFC2616 to create an API that strictly followed the "rules."
Ironically, learning the complexities of a given protocol or system and focusing on that alone has the potential to lead us down the road of inept teaching on the subject we call ourselves an "expert" of. That fancy RESTful API I built was stable, predictable and behaved to spec; and that was the problem.
The protocol choked the humanity out of the API and made it in some respects seriously difficult to use because of its rigidity. Some "got" it but most just got frustrated. I struggle with this because even as I explained the details of the specification a human connection was never made - I knew the complexities of REST but never grasped a simple understanding of it.
Being a better social developer today than I was "yesterday" and opening my mind to the fact that most anything that is complex has simple pieces I now have a desire to explain through simplicity and drop the obscurity. Frankly I don't have time to be obscure and explain things using the detailed schematics or protocols of technology - it's wasteful and I want to get things DONE.
With this in mind let's see if I can successfully do this with the fetch vs. pull question.
git fetch vs. git pull
Explained the old way (using obscurity and foreknowledge)
git-fetch : Right from the spec
Fetches named heads or tags from one or more other repositories, along with the objects necessary to complete them.
The ref names and their object names of fetched refs are stored in .git/FETCH_HEAD. This information is left for a later merge operation done by git merge.
When refspec stores the fetched result in remote-tracking branches, the tags that point at these branches are automatically followed. This is done by first fetching from the remote using the given refspecs, and if the repository has objects that are pointed by remote tags that it does not yet have, then fetch those missing tags. If the other end has tags that point at branches you are not interested in, you will not get them.
git-pull : Right from the spec
Incorporates changes from a remote repository into the current branch. In its default mode, git pull is shorthand for git fetch followed by git merge FETCH_HEAD.
More precisely, git pull runs git fetch with the given parameters and calls git merge to merge the retrieved branch heads into the current branch. With --rebase, it runs git rebase instead of git merge.
repository should be the name of a remote repository as passed to git-fetch(1). refspec can name an arbitrary remote ref (for example, the name of a tag) or even a collection of refs with corresponding remote-tracking branches (e.g., refs/heads/:refs/remotes/origin/), but usually it is the name of a branch in the remote repository.
Default values for repository and branch are read from the "remote" and "merge" configuration for the current branch as set by git-branch(1) --track.
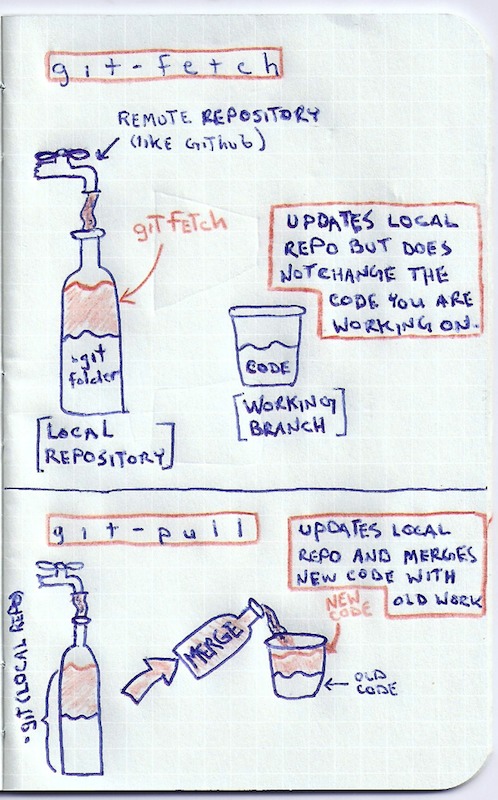
Taught the new way (using simplicity and hindsight)
See image above.